![]() دوشنبه ۱۴۰۱/۱۱/۰۳
دوشنبه ۱۴۰۱/۱۱/۰۳
![]() 338
338
![]()
![]() مطالعات باستانی
مطالعات باستانی
نوشته: Jean Druel and N.A. Mansour / Hazine
ترجمه: مرکز و کتابخانه مطالعات اسلامی به زبانهای اروپایی
اگر یک عربیدان یا عربپژوه هستید، به یاد بیاورید که تاکنون از کدام کتابخانههای دیجیتالی یا فهرستهای بایگانی استفاده کردهاید و سپس بشمارید که چه تعداد از آنها واسط کاربری و دادههایی به زبان عربی داشتهاند. تعداد اندکی از آنها به زبان عربی است، اگرچه فهرستها و ابزارها در زبان ترکی بیشتر است. به علاوه، طراحی این منابع اغلب برگرفته از ابزارهای تولیدشده برای محتوای اروپاییزبان و برای مخاطبان اروپاییزبان است، بیاینکه تغییر چندانی یافته باشد. در طراحی این ابزارها حتی احتمالش را هم ندادهاند که شاید محتوانامههای فکری دیگر که برخاسته از زمینههای فرهنگی متفاوتی است کارکرد متفاوتی داشته باشد و نیازمند معیارهای متفاوتی برای سازماندهی باشد؛ این تصور را هم نادیده گرفتهاند که فناوریها خنثیاند و فراگیر.

سنت فکری عربی بر محور تفاسیری شکل گرفته است که هرکدام بیانگر نظرات مختلف و گاه مغایر با یکدیگر است، اگرچه این تفاسیر اغلب بر گرد یک متن واحد به هم پیوند خوردهاند. بنابراین، مثلا برای مطالعه کتاب سیبویه باید با نسخههای تصحیحشدهای که از این متن موجود است آشنا باشید. ممکن است تفاسیری را هم که بر آن نوشته شده است لازم داشته باشید. طبیعتا منابع ثانویهای را هم که حول آن منتشر شده است میخواهید: مقالات و تکنگاریهای عربی، و نیز آنچه به دیگر زبانها منتشر شده است. اینجا شاید فهرست استاندارد موسسه پژوهشی شما چندان مفید نباشد. شما نیازمند فهرستی هستید که برای تأمین این مقاصد منبعشناختی تهیه شده باشد. فهرست الکندی که محصول «موسسه راهبان دومینیکن برای مطالعات شرقی[۱]» (IDEO) است بهترین راهحل را برای معضل نیاز به ابزارهای پژوهشی به زبان عربی ارائه میدهد، و ویژهی مخاطبان عربزبان با مقاصد مرتبط با سنت فکری عربی طراحی شده است. این فهرست راهحلی برای معضلات منبعشناختی ما هم فراهم میکند، خصوصا اینکه مرور محتوای آنلاین را به شکل موثرتری ممکن میسازد. هنوز خالی از عیب و نقص نیست، خصوصا اینکه حاوی تمام کتابهای عربی موجود نیست، ولی با الحاق مداوم دادهها و افزایش پیوسته کاربرانش این فهرست روزبهروز به موتور قدرتمندتری تبدیل میشود؛ فهرست الکندی اغلب اولین نتیجهای است که هنگام جستجوی اینترنتی به دنبال یک متن، مثلا کتاب سیبویه، مییابید. تیم فهرستنگار این ابزار بارها گسترش یافته است تا پاسخگوی حجم کاری آن باشد و تحت مدیریت محمد ملشوش[۲]، با تمام قوا پروژه را به پیش میبرد. در این مطلب مقدمهای برای کار با این سیستم به شما عرضه میکنیم و نیز یک دوره فشرده درباره استانداردهای فهرستنگاری هم ارائه میدهیم.
همهچیز در سال ۲۰۰۱ شروع شد که موسسه دومینیکن مطالعات شرقی تصمیم گرفت یک فهرست دیجیتال را برای جایگزینی فهرستهای مقوایی طراحی کند. در آن زمان، هیچ نرمافزاری موجود نبود که بتواند منابع را به خط عربی فهرست کند، چه رسد به اینکه بتواند اسامی مولفان را ثبت کند (که فقط به ضمیمه سنتهای مختلف نامنگاری تکمیل میشد، مثل شهرت، نسب، کنیه، لقب، نسبت، و غیره)، یا اینکه تاریخ هجری یا روابط بین آثار (تفسیر، ردیه، و…) را ثبت کند. لذا این موسسه تصمیم گرفت نرمافزار مخصوص خودش را طراحی کند. فلسفه اصلیشان این بود که فناوری باید خودش را با فرهنگ تطبیق دهد، نه برعکس. مغز متفکر این ابزار «رنه-ونسان دو گرانلونه[۳]» است که از سال ۱۹۹۵ کتابدار اصلی این موسسه به شمار میرود. او تا سال ۲۰۱۱ با داوطلبان فرانسویزبان برای شکلگیری این فهرست همکاری کرد، سپس با یک شرکت آیتی فرانسوی (۲۰۱۱-۲۰۱۳)، و سپس با یک شرکت آیتی مصری (۲۰۱۳-۲۰۱۵)، و سپس موسسه دومینیکن مطالعات شرقی تیم آیتی خودش را با استخدام توسعهدهندگان مصری تشکیل داد.

دلیل کارکرد خوب الکندی این است که موسسه دومینیکن مطالعات شرقی که در قاهره مستقر است کتابخانهای مختص مطالعه اسلام است؛ کتابخانه فیزیکی آن شامل ۱۵۰ هزار کتاب و ۱۸۰۰ عنوان مجله است. براساس خط مشی این موسسه تمرکز مجموعههای آن بر دوره پیش از سال ۱۰۰۰ میلادی و زبان عربی است، ولی اگر از هرکس که در دوره پس از سال ۱۰۰۰ فعالیت میکند بپرسید، با فروتنی خواهند گفت: مجموعه موسسه دومینیکن در آن دوره زمانی هم شدیدا قوی است. به عبارت دیگر، فهرست الکندی صرفا به دنبال سازگاری با یک پیکره فکری – یعنی سنت عربی – است و مشخصا امکان رفع نیازهای این سنت را دارد. بدین ترتیب کاربران خوششناس میتوانند با فشار دادن چند دکمه و سپس پر کردن نوارهای جستجو به بخشهایی از یک متن که در دیگر آثار تکرار شده است دسترسی بیابند. ولی همانطور که گفتیم، نام یک متن کلاسیک در سنت فکری اسلامی را در یک موتور جستجو وارد کنید و در همان چند صفحه نخست پیوندی را به یکی از بخشهای الکندی خواهید یافت. دومینیکنها گفتهاند که قصد دارند در نهایت منبع فرا-داده تمام کتابهای تصحیحشده و منتشرشده در سنت اسلامی بشوند و آن را در اختیار موتورهای جستجو بگذارند. بنابراین، حتی اگر به مجموعه فیزیکی این موسسه دسترسی نداشته باشید با فهرست الکندی به یک ابزار کاوشگر منبعشناختی دسترسی دارید. در مورد بسیاری متنها، استفاده از الکندی در قیاس با دیگر منابع مثل براکلمن (Brockelman) مسیر بسیار کارامدتری برای یافتن یک متن و متون منتشرشده در ارتباط با آن است، چرا که با این ابزار میتوانید متوجه شوید کدام منابع اولیه بصورت نسخههای تصحیح شده منتشر شدهاند، و نیز به تحقیقات مرتبط با آن اثر در دیگر زبانها هم دسترسی مییابید. بهعلاوه، ارتباط متقابل «مراجع» و افرادی که نویسنده یا ناشر متون هستند مشخص میشود و تصویری از روابط خانوادگی و علمی آنها به دست میآید.
پیش از اینکه به نحوه استفاده از الکندی بهعنوان یک ابزار منبعشناختی بپردازیم: مقدمهای بر نظامهای فهرستنویسی
اگر در حوزه تاریخ یا اسلامپژوهی آموزش دیدهاید، مهم است بدانید که، برای توصیف کتابها و مخطوطات، مدل مفهومی[۴] با قالب داده[۵] تفاوت دارد. تا حدودی، به این دلیل که مخطوطات دیجیتالیشده اهمیت روزافزونی در کار اسلامپژوهان یافته است، و اکنون که اینترنت به خزانه عظیمی از مطالب تبدیل شده است، همگی باید درباره فرا-داده و نحوه کارکرد آن آموزش ببینیم. اکنون، مقدمهای کوتاه درباره استانداردهای مختلف فهرستنویسی ارائه میدهیم.
تا سال ۱۹۹۸، مدل مفهومی رایج مدل «توصیف منبعشناختی استاندارد بینالمللی»[۶] (ISBD) بود. این مدل که در سال ۱۹۵۴ به ابتکار «فدراسیون بینالمللی انجمنها و موسسات کتابداری»[۷] ایجاد شده است، متشکل از ۹ حیطه است (۰: نوع رسانه، ۱: عنوان، ۲: ویراست، ۳: نقشهها و منابع الکترونیک، ۴: نشر، ۵: مطالب، ۶: سری، ۷: توضیحات، ۸: شناسه). مثلا یک ISBD کامل اینگونه است:
۰: متن: بدون واسطه
۱: راهنمایی برای نویسندگان مقالات پژوهشی، پایاننامهها و رسالهها: شیوهنامه شیکاگو برای دانشجویان و محققان / کیت ال. ترابیان؛ بازنگری توسط وین سی. بوث، گریگوری جی. کلمب، جوزف ام. ویلیامز، و تیم ویراستاری انتشارات دانشگاه شیکاگو.
۲: ویراست هفتم.
۳:
۴: شیکاگو: انتشارات دانشگاه شیکاگو، ۲۰۰۷.
۵: xviii، ۴۶۶ صفحه: مصور، ۲۳ سانتیمتر.
۶: (شیوهنامه شیکاگو برای نگارش، ویرایش و نشر).
۷: شامل ارجاعات منبعشناختی (ص. ۴۰۹-۴۳۵) و نمایه.
۸: شابک ۹۷۸-۰-۲۲۶-۸۲۳۳۶-۲ (کاغذ بدون اسید): ۳۵ دلار.
دادهها درون هر حیطه[۸] یک قالب مشخص دارد که «فهرستنویسی خوانا برای ماشین»[۹] (MARC) نام گرفته است و زیر-حیطهها[۱۰] و برچسبهای مخصوص به خود را دارد. هدف از تعریف یک قالب مشخص تسهیل ورود و خروج دادهها بین ماشینهاست. حیطهها و زیر-حیطهها اگر بهخوبی برچسب بخورند، جستجوپذیر میشوند. قالب MARC را هنریت آورام[۱۱] در دهه ۱۹۶۰ در کتابخانه کنگره ایالات متحده به همراه معرفی نظامهای محاسباتی در علوم اطلاعات ارائه داد. مزیت چنین سیستمی به دلیل مقدار بالای دادههایی است که در یک مدخل واحد امکان بارگذاری دارد. مثلا MARC استاندارد رایج در کتابخانههای سازمانی آمریکای شمالی است.
یک قالب دادهای دیگر «شرح بایگانی رمزی»[۱۲] (EAD) است. هدف از این قالب که در سال ۱۹۹۸ منتشر شد، شرح اسناد بایگانی و مخطوطات است. تمرکز این قالب نه بر متن (کتاب سیبویه) که بر شیء (میلان، کتابخانه آمبروزیانا، X 56 Sup.) است. اشیاء منحصربهفردند (یعنی با یک شماره قفسه معین در یک مجموعه شناسایی میشوند)، متنها چنین نیستند (حدود یکصد نسخه از کتاب سیبویه در جهان موجود است). یک قالب دادهای دیگر که گاهی برای شرح بایگانیها بکار میرود ولی عمدتا برای نسخههای الکترونیک متن توسعه یافته است قالب «ابتکار رمزگذاری متن»[۱۳] (TEI) است. نوع فرادادهای که معمولا در EAD و TEI رمزگذاری میشود از نقطهنظر «شیئی» بسیار غنی است (توصیف محتوای مخطوطات، معادل حیطه شماره ۵ در ISBD) ولی در سطح «متن» (حیطه ۱ ISBD) تهیدست است. نمونهای از TEI که شاید دیده باشید، خصوصا اگر با مخطوطات سروکار دارید، وبسایت فهرست است: فهرست تجمیعی مخطوطات اسلامی در بریتانیا.
در سال ۱۹۹۸، فدراسیون بینالمللی انجمنها و موسسات کتابداری یک مدل فهرستنویسی جدید با عنوان «نیازمندیهای کارکردی برای سوابق منبعشناختی»[۱۴] (FRBR) منتشر کرد، و در سال ۲۰۱۷ آخرین نسخه از مدل خود را با عنوان «حالت ارجاع کتابخانهای»[۱۵] (IFLA-LRM) راهاندازی کرد. این مدل مفهومی جدید مثل ISBD یک مدل تک-بعدی نیست، بلکه یک مدل چهار-سطحی است، که دادهها را از انتزاعیتر به مادیتر سطحبندی میکند: اثر، حالت، نمود، مورد[۱۶]. هر سطح میتواند به یک مرجع متفاوت منتسب شود، یک تاریخ متفاوت داشته باشد، و در همان سطح به دیگر مدخلها پیوند یابد. مثلا درباره کتاب سیبویه:
اثر: الکتاب، تألیف سیبویه در قرن دوم هجری.
حالت: ویراست علمی درنبورگ در ۱۸۸۱-۱۸۸۹.
نمود: چاپ مجدد به دست اُلمز در سال ۱۹۷۰ از روی نسخه پاریس ۱۸۸۱-۱۸۸۹.
مورد: ارائهشده به کتابخانه در سال ۱۹۸۹ از سوی جی. تروپو.
از لحاظ قالب داده (که مثلا در نمونه بالا، دادهها قالب ندارند)، در سال ۲۰۱۰ استاندارد جدیدی با عنوان «شرح و دسترسی منبع»[۱۷] (RDA) منتشر شد که مختص IFLA-LRM طراحی شده است.
این مدل جدید بسیار قویتر از ISBD است چرا که امکان ضبط روابط را در هر سطح فراهم میکند. درباره کتاب سیبویه، بهعنوان یک «اثر»، تفسیر، ردیه، تحشیه، و تحقیق نوشته شده است، و این هیچ ربطی به دادههای سطوح پایینتر ندارد. بنابراین یک رابطه «اثر» با «اثر» وجود دارد که مستقل از ویرایشی از کتاب سیبویه است که در دسترس داریم. میتوانیم این رابطه را یک رابطه «افقی» در سطح «اثر» بنامیم. این شبکه روابط «افقی» نمایانگر تاریخ فرهنگی متون است.
ولی به همین منوال، «ذیل» این «اثر» سیبویه میتوانیم ویراستهای علمی و ترجمههای مختلفی را ثبت کنیم. مثلا، در کتابخانه موسسه دومینیکن ۳ نسخه خطی، ۱۳ ویرایش، و ۶ ترجمه از همین کتاب سیبویه موجود است. و البته، این حالتها با هم مرتبطند: درنبورگ برای تهیه ویراست علمی خودش از میان نسخههای موجود روی نسخه arabe 3987 در کتابخانه ملی، پاریس کار کرد. به همین نحو، در سطح نمود، یک ویرایش واحد ممکن است بازچاپ، فتوکپی یا دیجیتالی بشود. این روابط را میتوان روابط «عمودی» از سطح «اثر» به «مورد» تلقی کرد، که نمایانگر تاریخ تصحیح متون است.
اگرچه هدف از قالب MARC هرگز شرح مخطوطات نبود و به همین دلیل EAD ابداع شد، هدف از قالب IFLA-LRM گردآوری هر دو نوع سند، یعنی نسخ خطی و نسخ چاپی ذیل یک مدل واحد است. در جهان بیسروصدای کتابخانهها جنگ ادامهداری بین کتابداران و بایگانیداران جریان دارد. کتابداران بر متون تمرکز دارند و بایگانیداران بر اشیاء. IFLA-LRM تلاش دارد با یکپارچهسازی هر دو منطق در مدل خودش این دو گروه را کنار هم بنشاند.
در سال ۲۰۱۱، درست پس از اینکه نسخه اول RDA منتشر شد، موسسه دومینیکن مطالعات شرقی تصمیم گرفت فهرست الکندی را بازآرایی کند تا بدین وسیله هم فهرستنویسی مخطوطات و هم فهرستنویسی کتابهای چاپی را براساس مدل LRM و با استفاده از قالب داده RDA در فضای آنلاین دسترسپذیر کند. وقتی محققان پایگاه داده الکندی را باز میکنند، ذیل یک «اثر» مشخص به نسخههای خطی، ویرایشها و ترجمههایش («عمودی») و به تمام دیگر «آثار» مرتبط با آن («افقی») دسترسی مییابند. مثلا، در مورد کتاب سیبویه: ۱ اثر، ۲۲ حالت (۳ نسخه خطی، ۱۳ ویرایش، و ۶ ترجمه)، ۲۹ نمود، ۳۰ مورد. و این «اثر» در رابطه با ۲۳۲ «اثر» دیگر (تفسیرها، ردیهها، و…) قرار دارد، که آن آثار هم به نوبه خودشان تفسیر، رد، و تحقیق شدهاند (روابط «افقی» اثر به اثر بیشتر)، و نیز ویرایش، ترجمه، و بازچاپ شدهاند (تاریخ ویراستاری «عمودی» هر اثر). میخواهیم ببینیم که چگونه تمام این دادهها میتوانند در جمعآوری دادههای منبعشناختی به شما کمک کنند.
آنچه باعث شد مدل FRBR (و بعدا LRM) برای موسسه دومینیکن بسیار جذاب شود این است که این کتابخانه اغلب بیش از یک ویرایش از یک متن واحد را در اختیار دارد، ضمن اینکه ما میخواهیم روابط بین «آثار» را هم ثبت و ضبط کنیم، که ویژگی مهمی در میراث اسلامی به شمار میرود.
مثل هر فهرست دیگری، استفاده شما از این فهرست قرار است در نهایت تابع فرایند فکری شما و ریزهکاریهای پروژه خاص خودتان باشد. ماجرا عمدتا ور رفتن با این نرمافزار و عادت کردن به آن است. با این حال، روشهایی را برای شروع کار میتوان مشخص کرد. ما کتاب سیبویه را کنار میگذاریم و به سراغ متن عبادتنامه کلاسیک دلائل الخیرات نوشته امام محمد بن سلیمان الجزولی میرویم تا بر محور آن جستجو کنیم. به دنبال نسخههای تصحیحشده این متن، منابع ثانویه به زبانهای مختلف، و شرحهایی که بر خود این متن نوشته شده است میگردیم. توجه کنید که ما برای این نمونهها از متن حروفگردانیشده ساده استفاده خواهیم کرد.
روش ۱: مستقیم به سراغ متن مورد استفادهتان بروید

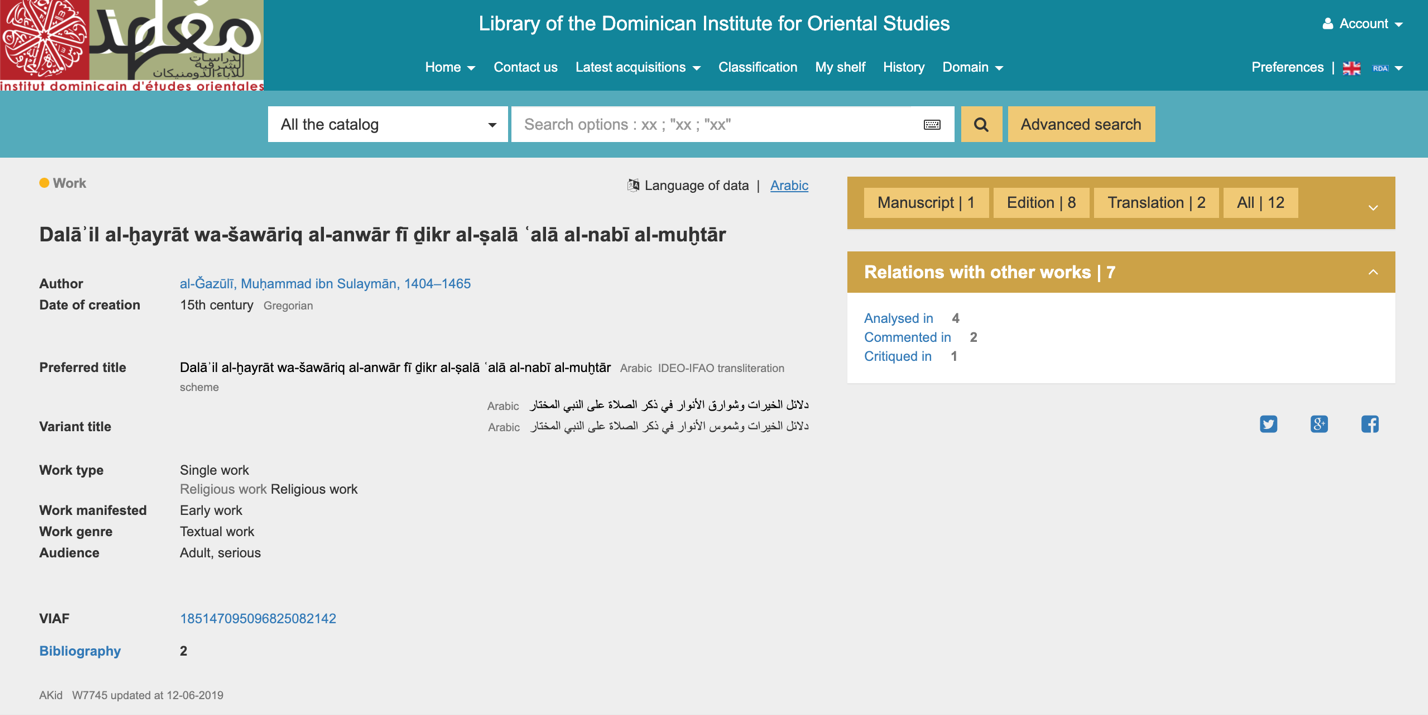
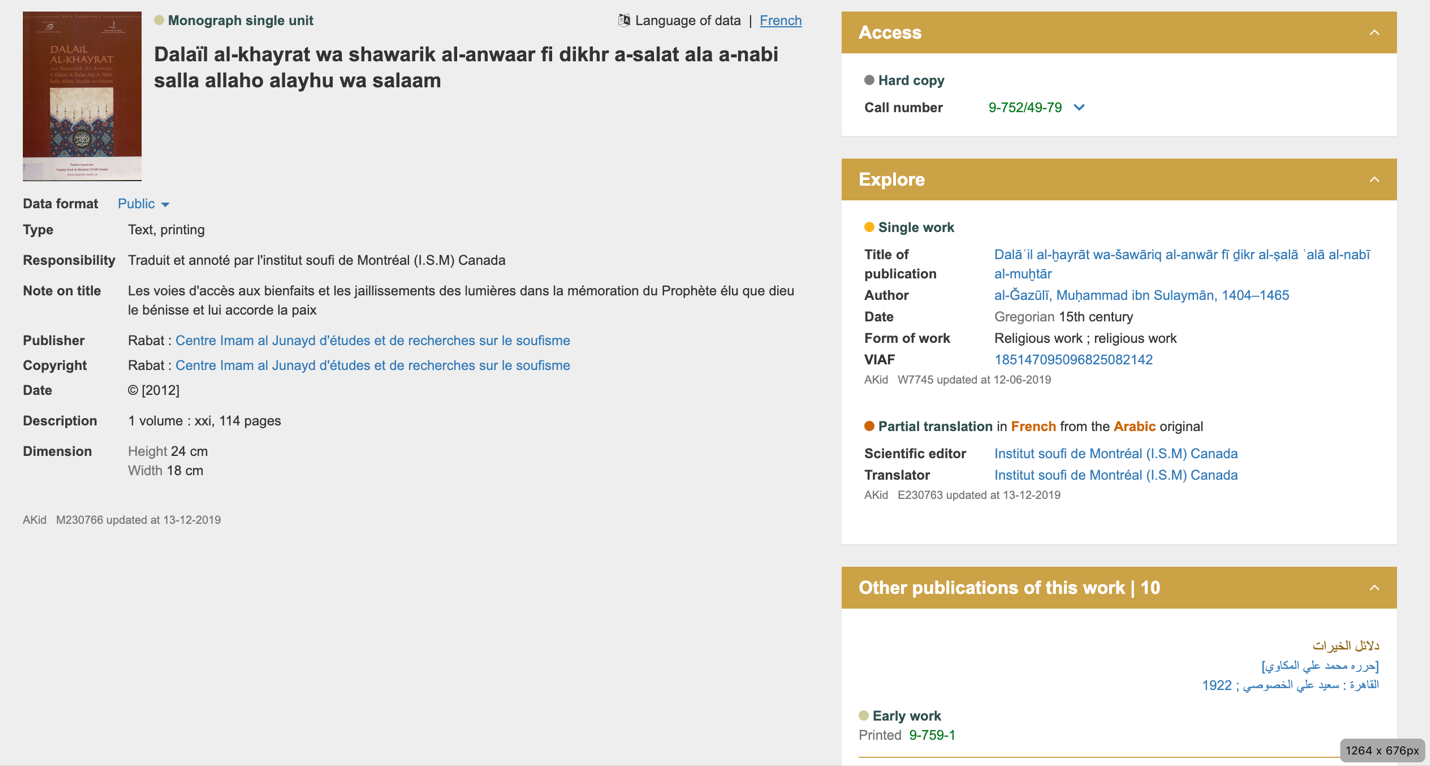
* حتما توجه کنید که سیاست فهرست الکندی درباره حروفگردانی اخیرا بازنگری شده است. بطور پیشفرض، موسسه دومینیکن براساس همان الفبای خود منبع کدگذاری میکند، هر الفبایی که باشد. اگر تمام انتشارات یک مولف مشخص به خط عربی باشد، موتور جستجو هیچ نتیجهای را بهصورت حروفگردانیشده نشان نمیدهد. ولی اگر آثار این مولف دارای ویراستها، ترجمهها، یا تحقیقاتی به زبانهای دیگر باشد، موسسه دومینیکن مدخل مربوط به آن را ایجاد خواهد کرد. اخیرا، از آنجا که موسسه دومینیکن اکنون با «کتابخانه ملی فرانسه» همکاری میکند، ما معمولا محتوای بیشتری را حروفگردانی میکنیم، که عناوین آثار و اسامی مولفان را هم در بر میگیرد، حتی اگر صرفا به زبان عربی باشند. قاعده دیگر این است که موتور جستجو دادهها را فقط به همان زبانی که برای جستجو استفاده شده است نشان میدهد، اگرچه تمام دادهها در این پایگاه داده به هم متصلاند. مطمئنترین راه برای دریافت نتایج جامع، جستجو به زبان عربی است (که باعث اجتناب از مشکلات حروفگردانی هم میشود) و سپس حرکت به سمت سطوح بالاتر دادهها مثل رکورد مولف یا رکورد اثر است. در واژگان فنی IFLA-LRM، این یعنی جستجو در «تمام فهرست» (All the Catalogue) فقط «نمودها»ی موجود در همان زبان مورد استفاده برای درج عبارت جستجو را نمایش میدهد.
روش ۲: جستجو براساس مولف
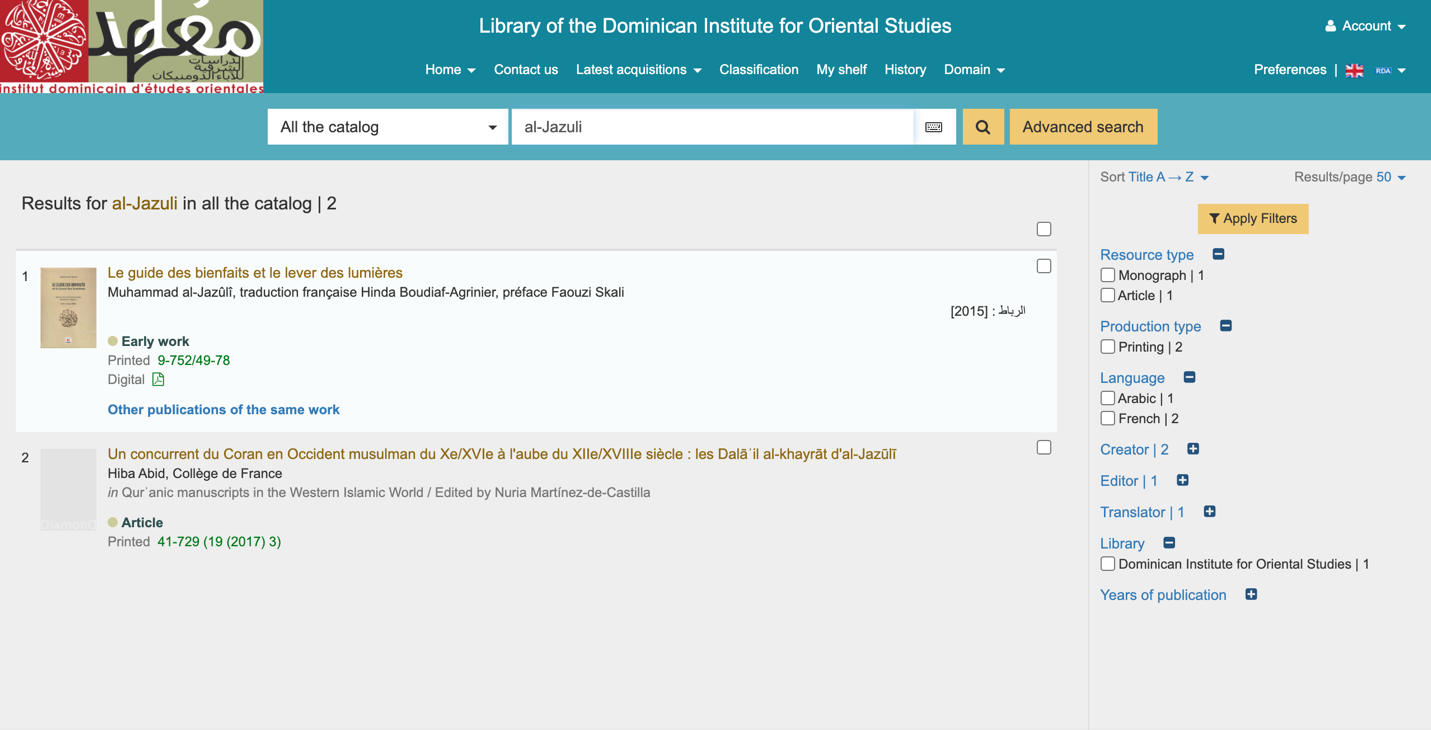
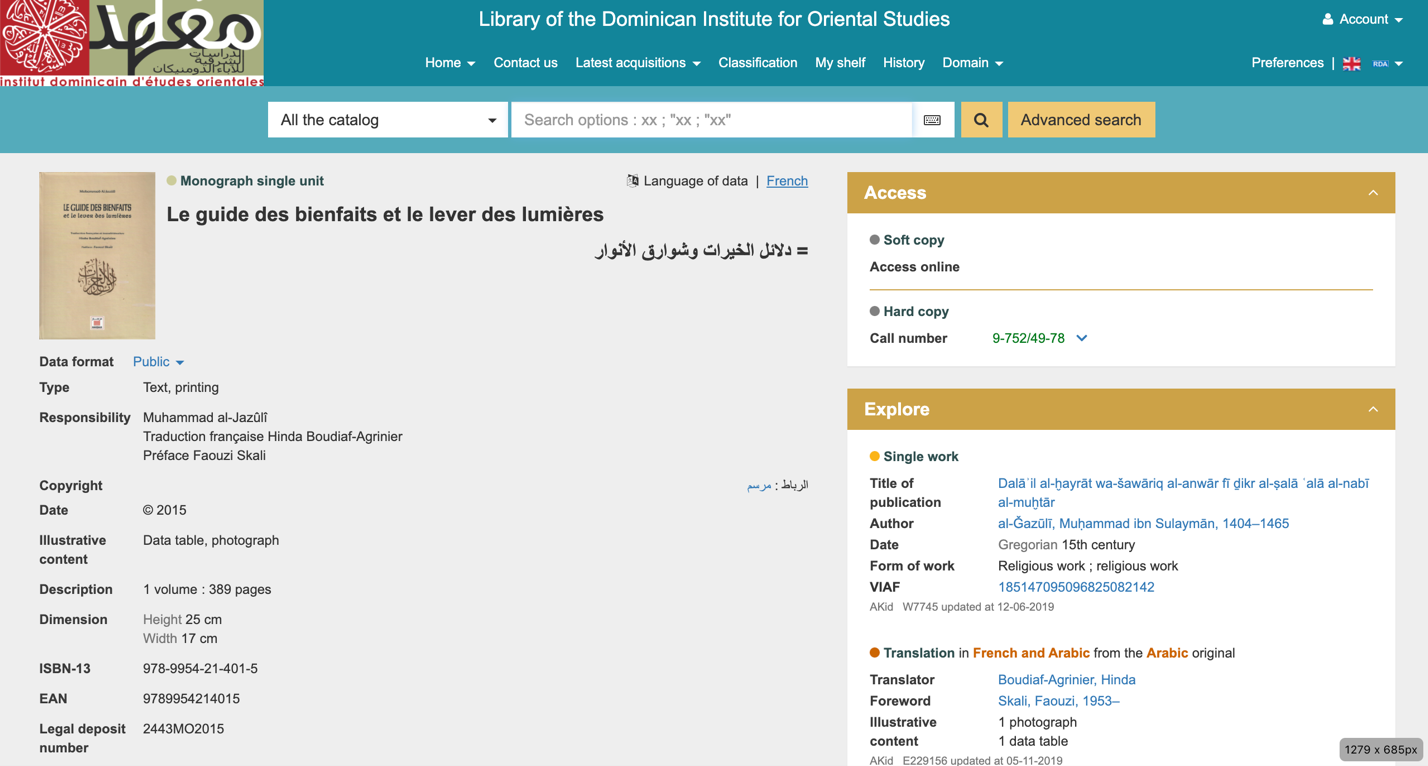
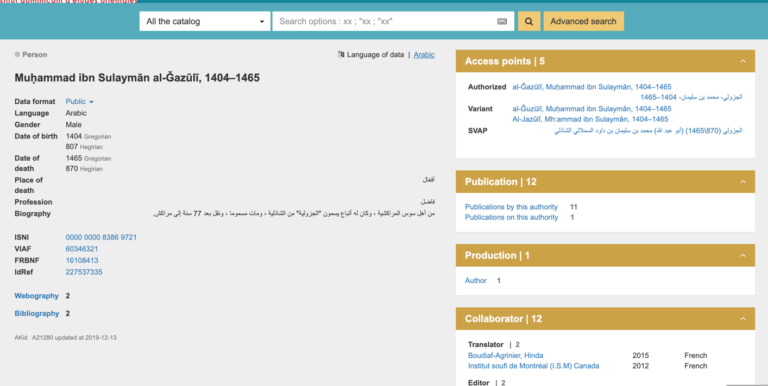
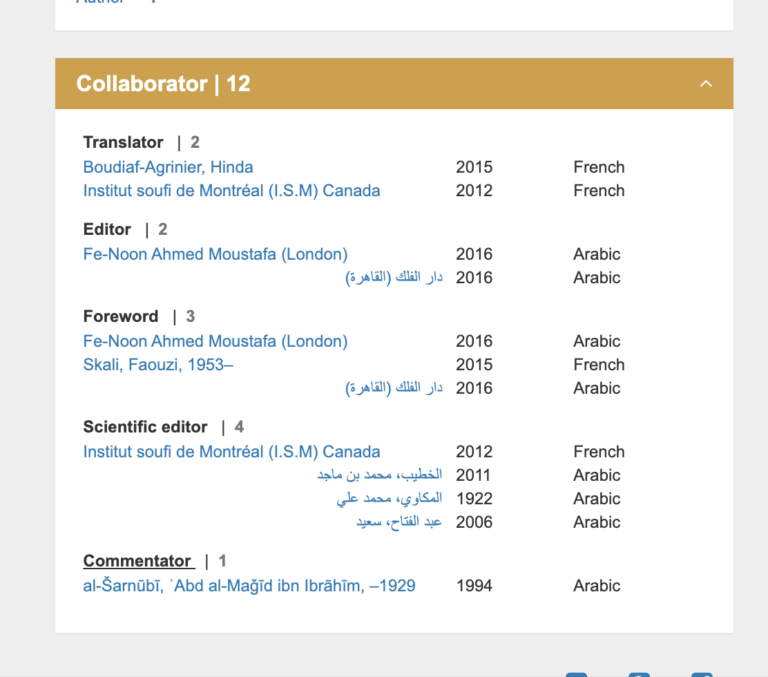

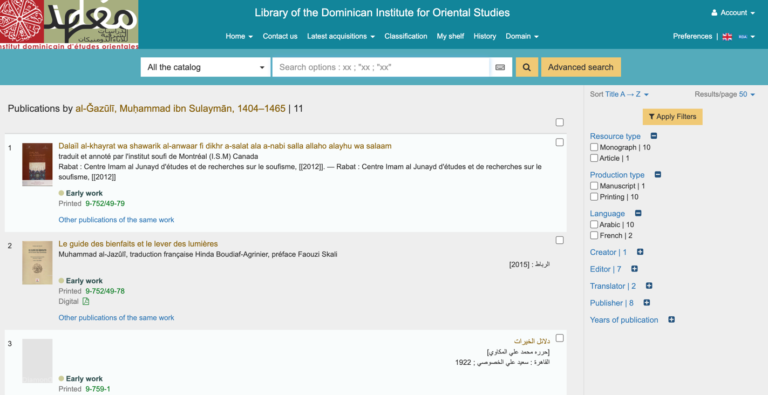
الکندی و آینده
در آینده، موسسه دومینیکن مطالعات شرقی تمایل دارد الکندی را در اختیار کتابخانههای تخصصیتر مطالعات اسلامی و خصوصا کتابخانههای مخطوطات قرار بدهد. تاکنون، علاوه بر موسسه دومینیکن، سه کتابخانه از آن بهره میگیرند: «موسسه مخطوطات عربی» در قاهره، «کتابخانه اسلامی جورجیو لا پیرا» در پالرمو، و «موسسه باستانشناسی فرانسوی» در قاهره برای مجموعههای خطیاش. کتابخانه واتیکان هم برای مخطوطات عربیاش در حال مذاکره است.
در پایان، الکندی احتمالا به «گوگل متون اسلامی» تبدیل نخواهد شد، ولی اگر همگام با ابزارهای «وب معنایی» و شناسههای بینالمللی برای مولفان و آثار پیش برود، میتواند سهم بزرگی در آسانسازی فعالیتهای دانشوران علوم اسلامی از طریق ابزارهایی به همان سادگی موتور جستجوی گوگل ایفا کند.
[۱] Dominican Institute for Oriental Studies (IDEO)
[۲] Mohamad Malchouch
[۳] René-Vincent du Grandlaunay
[۴] conceptual model
[۵] data format
[۶] ISBD (International Standard Bibliographic Description)
[۷] IFLA (the International Federation of Libraries Associations and Institutions)
[۸] field
[۹] MARC (Machine Readable Cataloguing)
[۱۰] sub-fields
[۱۱] Henriette Avram
[۱۲] EAD (Encoded Archival Description)
[۱۳] TEI (Text Encoding Initiative)
[۱۴] FRBR (Functional Requirements for Bibliographic Records)
[۱۵] IFLA-LRM (Library Reference Mode)
[۱۶] Work, Expression, Manifestation, Item
[۱۷] RDA (Resource Description and Access)
لطفا نظر خود را در مورد این مطلب بنویسید
نظرات شما
نظری برای این مطلب ثبت نشده است
مشاهده بیشتر
اطلاعات تماس
با عضویت در خبر نامه
از آخرین مطالب ما، باخبر شوید...